
 Seongbuk-gu, KR
Seongbuk-gu, KR
Activity
Challenge Categories
Challenges Entered

Latest submissions
See All| graded | 165448 | ||
| failed | 165433 | ||
| graded | 165427 |
| Participant | Rating |
|---|---|
 wac6er
wac6er
|
0 |
 loreto_parisi
loreto_parisi
|
0 |
| Participant | Rating |
|---|
Music Demixing Challenge ISMIR 2021

No attribute 'SIGALRM' issue in Windows 10
Over 3 years agoHello,
Is there anyone who have encountered the error below when run the base code of the MDX challenge on Windows 10?
AttributeError: module 'signal' has no attribute 'SIGALRM'
I and several users have encountered this: https://github.com/kuielab/mdx-net-submission/issues/1
I think it is caused by the ambiguous name of library ‘signal’.
SIGALRM exists in signal.pyi
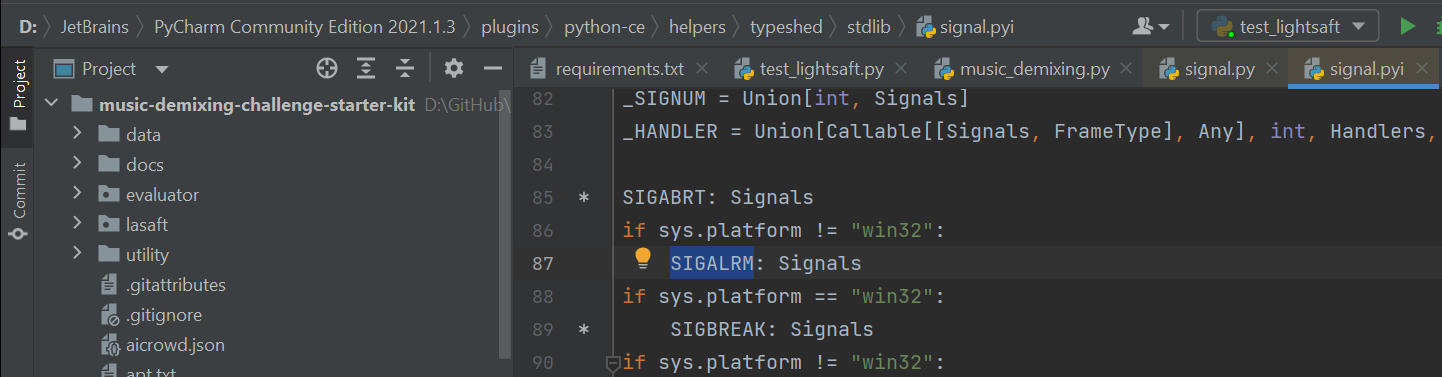
but it does not exist in signal.py.
When I run it in Windows 10 env, it tries to access with signal.py instead of signal.pyi,
causing the error.

I guess many Windows users suffer from this issue, not limited to the MDX challenge.
Will AIcrowd have a plan to fix this bug?
or I think I should add some comments in our repository to warn the potential error.
Thank you in advance.
Woosung Choi.
Can I use GPU for prediction?
Over 3 years agoHi @Li_Xue_Han and @jyotish,
It is a bit embarrassing since I did not expect that gpu is available.
I believe that many participants have read the previous discussion from Hardware specifications, where @StefanUhlich has not mentioned the availability of gpu.
After reading Uhlich’s response, our models have been optimized in the cpu environment concerning the time limit, giving up the advantage of gpu usages.
Questions about leaderboards A and B
Over 3 years agoDear Dr. @StefanUhlich and @shivam
I have similar questions related to this issue.
-
Can we tune hyper-parameters by analyzing the SDRs measured by AICrowd? For example, what if we choose the best checkpoint after submitting top-3 checkpoints? Should it be submitted to A or B? Or is this not allowed?
-
Challenge Rules said, “one for systems that were solely trained on the training part of MUSDB18HQ.”
However, there are two versions of splits in musdb18: (84 training, 16 validation, 50 test) and (100 training, 50 test) as far as we know. I am not sure this means whether we should use the predefined (86 training, 14 validation, 50 test) split for leaderboard A or not. Can we use customized splits in 100 training tracks to submit a model to leaderboard A? - for example, 95 training items and five validation items?
Best regards,
Woosung Choi.
What might cause a "Scoring failed"?
Over 3 years agoI guess that the updated validation phase recently added might have a too strict threshold.
It seems that the models, which have passed the entire evaluation phases before, are currently filtered out after the update.
Hi @shivam, sorry to bother you gain, but could you please let me know the threshold used for time-out submission filtering?
:genie: Requesting feedback and suggestions
Over 3 years agoGood news! Thank you for your hard working!
The team members could not access the git codes submitted by the team organizer?
Over 3 years agoHello @ant_voice1, you can manually set the accessibility in your repository.
Invite your team members!
:genie: Requesting feedback and suggestions
Over 3 years agoHi @shivam,
Many participants have struggled due to the time-out problem.
My team also got frustrated when we encountered inference failed at 100%.
Since some submissions failed at 100% inferences, I think the last track is the longest one.
So why don’t you add an additional phase for filtering time-out submission out with the longest track?
Then, participants will not have to wait for the entire inferences.
It will also reduce the evaluation system’s workload because it does not have to process all the tracks for time-out submissions.
I always appreciate your support.
Best,
Woosung Choi.
Can someone tell me where the best stopping point for my model would be please (graph inside)
Over 3 years agoHello @kimberley_jensen,
I highly recommend submitting as many checkpoints as you can during this competition.
The early stop algorithm might not even help you to find the best checkpoint you have to submit.
It usually depends on your model, the number of parameters, the validation metric (L1, L2, …), the optimizing algorithm you are using, the estimation method (magnitude mask estimation, direct waveform estimation, …), etc.
The practical way to reduce the gap between your expectation and the score measured by the AIcrowd system is as follows:
submit many checkpoints and adjust your model, the way to select the optimal checkpoint, …
I hope this is helpful for you.
Best,
Woosung Choi
[Announcement] Spleeter Baseline should have external dataset "true"
Almost 4 years agoThank you very much for your hard-working Shivam!
It is just a personal opinion, but I think there are still many people who submit models trained with extra datasets to leaderboard A.
Also, models based on pre-trained models such as demux-extra (https://github.com/facebookresearch/demucs/blob/2404fa029137b39d66a46db65958cffd50bed6ad/demucs/pretrained.py#L23) and tasnet-extra (https://github.com/facebookresearch/demucs/blob/2404fa029137b39d66a46db65958cffd50bed6ad/demucs/pretrained.py#L26) must be placed in leaderboard B.
Is the submission process still open?
About 3 years agoHi @sevagh and @vrv
I have the same question with @sevagh.
I submitted one by pushing a tag starting with ‘submission.’
There was no error reported but no evaluation process was triggered.
Was it suspended for 2022?